The cost to develop software has collapsed over the last 50 years — and demand has exploded.
LLMs now let non-engineers build working software, but most AI builders break down during real project maintenance.
Rails is uniquely suited for AI-driven development because it gives LLMs a deterministic, opinionated structure — the one thing AI agents need to reliably modify and maintain code.
The remaining barrier is accessibility: Rails has historically been hard for non-technical people to install, run, or even start.
Leonardo removes that barrier by giving users a zero-setup, browser-based Rails environment powered by an AI operator-agent — no terminal, no VSCode, no local environment required.
Leonardo combines the accessibility of vibe-coding tools (Lovable/Bolt/Replit) with the power, stability, and maintainability of Rails.
This is how the next 1,000,000 Rails apps will get created, by people who deeply understand real-world problems, not just engineers.
My goal: help accelerate the next 1 million next Rails apps be created, from non-traditional developers using LLMs.
Introduction: The cost to develop software has steadily decreased
Since 1970, the cost to develop software has plummeted. Higher level languages, better tooling, and sharing of knowledge has led to higher quality software that is more affordable.
Open Source frameworks & development infrastructure decrease the amount of time and effort to create new custom software.
It’s hard to objectively measure the cost to develop software. Counting the lines of code is misleading, because good engineers actually often write less code, and also comparing across programming languages and frameworks is misleading.
For example, to print Hello World in C is more lines of code than to print Hello World in a higher level language like Python. Here’s a good illustrative example on reading errors from a file.
High Level (Python):
Straightforward, expressive, hides the ugly parts:
count = 0
with open("log.txt") as f:
for line in f:
if "error" in line:
count += 1
print(count)
Lines of code: 6 Memory management: Automatic I/O abstraction: Built-in String ops: Built-in Error handling: Could be added, but not required for basic functionality Developer mental load: Minimal
Low Level (C):
You handle your own memory, buffers, file pointers, comparisons, and cleanup:
Lines of code: ~35 Memory management: Manual (free, malloc via getline) I/O: Manual (fopen, getline, fclose) String ops: Manual (strstr) Error handling: Required Developer mental load: High — and mistakes cause security bugs
____
While this example illustrates how software has gotten easier, this also helps illustrate why lines of code as an objective metric is misleading.
To solve this problem, an engineer from IBM Allan Albrecht, invented function point analysis.
Albrecht’s insight was to measure the size of the problem being solved, not the amount of code used to solve it.
So he created the now-standard 5 categories:
External Inputs
External Outputs
External Inquiries
Internal Logical Files
External Interface Files
Weighted → summed → Function Points.
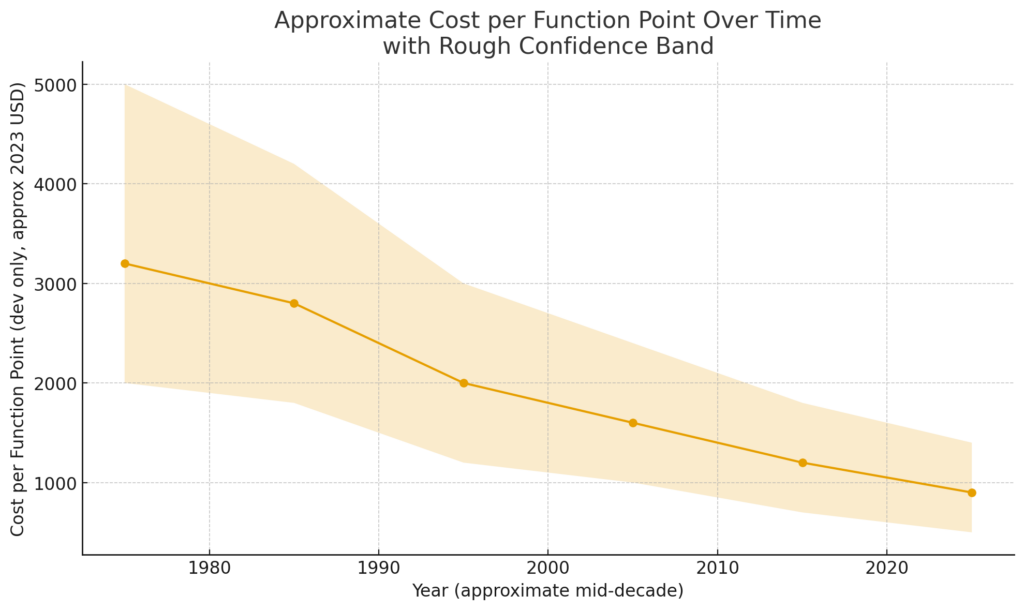
Software companies have also tracked & published data around their own function points, so we have some reference as to how this has evolved over time. While there’s no comprehensive data source created, we can still derive a rough approximation of cost per function point over time, since the 70s.
Sources: Capers Jones, The Economics of Software Quality, and ISBSG / Czarnacka-Chrobot (case study using ISBSG “Software Project Costs”).
It’s safe to claim that since the 1970s, the cost has dropped approximately by a factor of 3, despite growing costs of labor for software engineers.
These productivity gains come from better tooling, open source projects, online knowledge sharing, and the rise of higher level programming languages like Python, Ruby, and JavaScript.
As is true for any technology: as the cost decreases, the demand increases.
Demand for New Software is Still Growing.
The world has a plethora of problems that can still be addressed by new software. But the cost to develop new software has always been a bottleneck, because engineers are expensive, and code is complicated.
With the costs to develop new software decreasing, along with new AI capabilities such as AI vision, LLMs, and generative AI, we can now build software that was previously unimaginable, for much cheaper than ever before in history.
Increasingly, software isn’t being created by just professional developers. A new class is emerging, known as “citizen developers.” This class of people do not have Computer Science degrees, and they rely increasingly on other tools to generate code for them.
Before LLMs, a plethora of no-code and low-code tools like Bubble, Make, and even open source projects like WordPress made building new software accessible. But as AI scaled, LLMs have become extremely good at writing code.
LLMs help non-engineers build software.
This has led to an explosion in popularity of “vibe coding” tools, such as Lovable.dev, Bolt.new, and Replit. You can simply type your idea into an AI chat box, and have a fully functioning software prototype in a matter of seconds.
But LLMs writing code isn’t all sunshine and roses, there are difficult problems that arise, such as:
But despite these problems, millions of “citizen developers” are continuing to adopt and pay for AI generated coding tools. As AI models become increasingly affordable and capable, these problems will become easier to solve.
Another way we can reduce these errors is by helping the LLM out, the same way we’d help a Jr. Software Engineer out: give it the right tools. That’s where a framework like Ruby on Rails comes into play.
My Thesis: Rails is the perfect framework for non-engineers to build software using LLMs
There are very strong, structural advantages of Ruby on Rails, as explained by it’s creator David Heinemeier Hansson:
It brings us to the ideal of The One Person Framework. A toolkit so powerful that it allows a single individual to create modern applications upon which they might build a competitive business. The way it used to be.
There’s so much to learn these days, if you want to be an expert in all the latest tools and techniques. The conventional path [to software engineering], as paved by solutions extracted from giant tech companies, is a journey akin to The Oregon Trail. You might well die of dysentery before you ever get to your destination!
Rails 7 seeks to be the wormhole that folds the time-learning-shipping-continuum, and allows you to travel grand distances without knowing all the physics of interstellar travel. Giving the individual rebel a fighting chance against The Empire.
You simply can’t play by the same rules against an opponent exponentially stronger than you.
The key engine powering this assault is conceptual compression. Like a video codec that throws away irrelevant details such that you might download the film in real-time rather than buffer for an hour.
Rails + LLMs Are A Perfect “Unfair Leverage Stack”.
If a non-engineer is going to build real software with an AI assistant, Rails is simply the highest-probability path to success.
Why?
Rails has batteries-included: migrations, ActiveRecord, jobs, mailers, caching, etc.
Rails already embodies 20 years of engineering best practices, so the LLM doesn’t have to reinvent fundamentals.
Convention over configuration massively reduces hallucination surface area.
Rails gives LLMs a predictable file structure, which is critical for deterministic code modifications.
Rails’ monolith avoids the fragility of microservice-style code generation.
Rails robust ecosystem of Gems such as Devise for security/auth patterns reduce catastrophic LLM mistakes, and provide powerful, working code, on day 1.
Non-engineers using LLMs do not want:
Modern JS dependency churn
18 dependencies for basic CRUD
Vite → Next → Bun → Node → pnpm → esbuild → whatever
They want:
One framework
One mental model
One cohesive toolkit
The Rails superpower is not just technical — it’s psychological. It removes 80% of the cognitive load that overwhelms not only engineers, but also LLMs.
This is a truth nobody in the JavaScript hype cycle wants to admit, and it’s exactly why Rails is superior for AI coding agents.
The Real Problem Isn’t Code Generation — It’s Project Lifecycle
Existing vibe coding tools can generate code, but cannot maintain code.
That’s their fatal flaw.
LLMs fall apart when:
File structures change unpredictably
Auth patterns drift
API shape diverges
The app becomes a tangle of idiosyncratic user prompts
Rails solves this by giving the LLM:
Deterministic MVC structure
Deterministic naming conventions
Deterministic routing
Deterministic file placement
LLMs thrive when the environment is deterministic. Rails is deterministic.
But determinism alone isn’t enough.
Ruby on Rails has always had one major weakness: it’s hard to start. Rails is unbelievably productive once you’re inside it, but getting there traditionally requires terminals, version managers, local databases, and dev environments that instantly overwhelm non-technical people.
This is the real reason browser-based AI coding tools exploded. Not because their stacks are better, but because they’re accessible.
Cursor and Claude Code are incredible tools, but most people don’t have VSCode installed. Most have never touched a terminal. They see a blinking prompt and shut their laptop.
This is where tools like Lovable.dev, Bolt.new, and Replit actually shine: they’re frictionless.
You click a button and you’re building software in the browser. No installs. No setup. No environment debugging. My 63-year-old mother could start a project that way.
Rails doesn’t have this yet.
If Rails is going to empower a new class of builders — if the next million Rails apps will be created by people outside traditional engineering — then Rails needs something radically simpler:
A brand-new Rails app that spins up instantly in the browser
Zero installation or local environment
A simple chat interface where they never have to view or edit the code manually
You need an AI agent that can operate Rails (run it, modify it, migrate it, refactor it, etc.) inside a stable environment where the user never touches the terminal.
This is exactly what Leonardo provides.
Leonardo runs a full Rails app in the cloud, accessible entirely through the browser. It gives users a chat interface to create and modify features without ever installing Ruby, opening VSCode, or configuring PostgreSQL.
And because Rails is a monolith (concise, high-level, migration-aware, schema-aware), Leonardo’s agent can maintain the app over time without collapsing it. It doesn’t rely on Supabase or an external backend. It doesn’t generate sprawling TypeScript/React projects that explode token usage. Rails is far more token efficient and far more structurally predictable for an LLM.
We also did something fundamentally different with pricing: users pay exactly the LLM token cost, no markup.
Or they can bring their own API keys entirely.
This makes Leonardo dramatically more cost-effective than Lovable, Bolt, or Replit. But, more importantly, Rails + Leonardo produces software that is maintainable, stable, and evolvable.
Leonardo gives you the accessibility of browser-based AI builders… with the power, determinism, and maintainability of Ruby on Rails.
This is the missing layer the ecosystem needed.
For the first time in history, the bottleneck to building software is no longer technical. It’s imaginative. The world is full of people who understand business problems deeply, but cannot code. If we give them a stable, powerful, opinionated framework, we unlock a new class of builders!
The next million Rails apps will not come from Silicon Valley dev teams. They will come from accountants automating workflows, operations leads replacing spreadsheets, founders validating ideas, and domain experts who’ve never touched a terminal.
If you’re a founder, operator, freelancer, or domain expert with a problem you wish were automated, then build it with Rails and an AI partner. Leonardo is the first step.
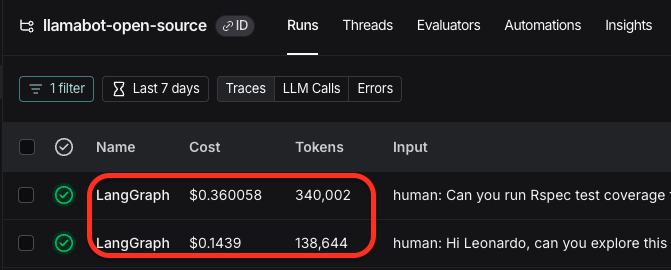
Last night, I noticed these emails where Anthropic was charging my credit card for $13-$15, multiple times a day.
When I dug into this more, I saw that yesterday I had 47M inputs tokens for Claude!
And it cost me ~$50. This was shocking because I recently switched to Claude Haiku 4.5 to avoid this precise issue.
Leonardo is a hungry beast for tokens.
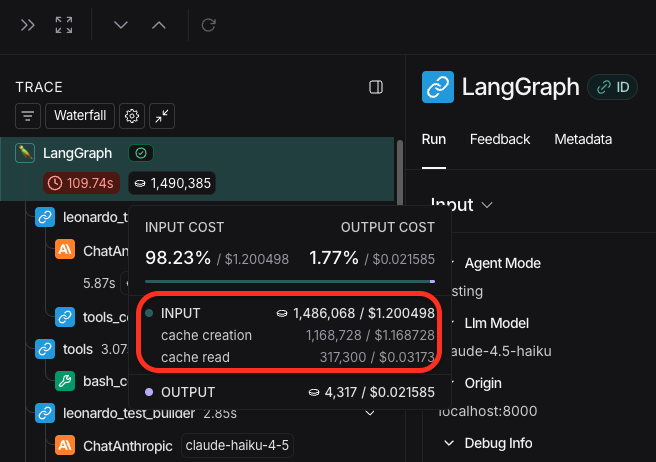
I recently gave Leonardo the ability to write & run Rspec tests. And these tests take a lot of input tokens, especially if it’s dumping all your SQL transaction queries into the LLM context window. 🤷
But beyond turning off verbose SQL statement logging to reduce the amount of input tokens, another thing stood out to me on Anthropic’s pricing page.
Cached tokens are only $0.10 per million tokens! That’s 1/10th the cost. That sounds amazing to me, so I decided to implement it into Leonardo’s test building mode.
But first, let’s just discuss costs and do an experiment.
Notice how many tokens this uses just to ask it to explore my project and tell me about it.
Claude Haiku ingested 139K of tokens. (The system prompt alone is 16K tokens).
BUT, notice it had 8 turns! Meaning, this system prompt got fed back into Claude Haiku 8 times! 16K * 8 = 128K tokens, just on ingesting the system prompt alone!
That single turn cost 15 cents. And as the conversation drags on, the cost skyrockets, because at each message, it continuously ingests the entire conversation, including all the previous tokens.
If this was Claude Sonnet, it’d be even more expensive. This 139K tokens would cost 45 cents. But just wait, it gets worse.
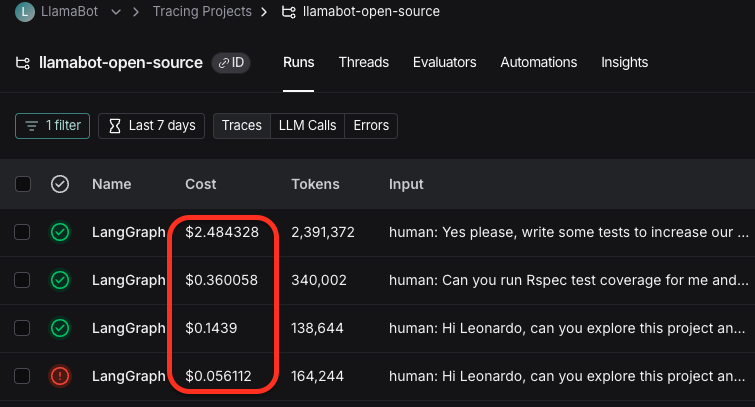
I then asked Leonardo to run Rspec, and the cost jumped up again. Now with 340,000 tokens, it cost 36 cents for this additional message from the user.
For Claude Sonnet, this would have been $1.08.
And now, this is where my budget for groceries really gets murdered: asking Leonardo to implement unit tests where there’s gaps in coverage!
I asked Leonardo to implement new tests to boost test coverage. And Leonardo sent over 50!! messages, and implemented a handful of new tests using RSpec.
This run cost $2.48.
With Claude Sonnet, this would have been approximately $7.44.
Now, you can see how spending 12 hours on this yesterday, why I ended up with a bill of $47, (even when using the affordable Claude Haiku). This makes both me and my girlfriend sad. (Sorry babe, we have to cancel our plans to see Wicked 2, Leonardo ate all our money).
But.. I don’t want to overly complain, because this is still pretty awesome.
Even if it’s expensive, Leonardo generated 1,244 new lines of high quality Ruby/RSpec code that tests our Ruby on Rails project. It boosted test coverage and wrote over 80 new tests.
To do this, it ingested thousands of lines of code to understand the project well enough. I mean, just look at this beautiful Ruby code.
Pre LLMs, assume a Jr. Dev spent a full working day doing this. If you’re paying said Jr. Dev a 75K/year salary, we’re looking at ~$322.95 for that full days worth of work.
So even if we used Claude Sonnet, and it cost $10 for this, that’s an order of magnitude lower on cost, and multiple orders of magnitude lower on time efficiency.
That being said, I’m a broke founder.
So if I’m choosing whether to pay API credits over paying my groceries (not hyperbole if this is $50/day in token costs), then I’m going with groceries so I don’t starve.
Luckily, I can have my LLM tokens and eat them too, by implementing something called prompt caching.
The cost savings are dramatic, let me show you.
The main code change was to switch off LangChain’s SystemMessage object, and use good ol’ JSON.
At first, Claude Code tried to add in additional_kwargs={"cache_control": {"type": "ephemeral"}} as an input argument to the SystemMessage constructor, but I wasn’t able to get it to trigger output.
In LangChain’s documentation on Anthropic Caching, they actually have the example where they just use a JSON object for the system message, so that’s what I decided to go with.
from langchain_anthropic import ChatAnthropic
model = ChatAnthropic(model="claude-sonnet-4-5-20250929")
messages = [
{
"role": "system",
"content": [
{
"type": "text",
"text": "Below is some long context:",
},
{
"type": "text",
"text": f"{long_text}",
"cache_control": {"type": "ephemeral"},
},
],
},
{
"role": "user",
"content": "What's that about?",
},
]
response = model.invoke(messages)
response.usage_metadata["input_token_details"]
As a reminder, here’s the costs without caching:
And here’s the exact same experiment ran, but with caching enabled:
By just caching the system prompt, I cut the cost down to almost half of what it was previously!
What’s awesome too, is that I’m only caching the system prompt.
If I were properly caching the entire thread of messages, the cost would come down even more.
But, since I’m a lazy founder just trying to ship capability increases (such as making Leonardo 10x smarter for coding Ruby on Rails projects), I’ll hold off on more LLM caching work until I get my next crazy high bill from Anthropic. 🙂
In summary, if you’re a broke founder worried about the costs of groceries, yet you’re hopelessly addicted to using Claude to write code, and especially if you’re writing your own system prompts, consider implementing Anthropic’s prompt caching mechanism.
I’ve decided to add a new agent mode into Leonardo, that can write Rspec unit tests for self-verification.
Here’s the deep-research report that led to me choosing RSpec vs. Minitest.
I didn’t know about the concept of mutations in unit tests, but it sounds extremely powerful and unique to Ruby’s testing ecosystem. This could be huge for agents that are self-verifying, and can help agents write extremely high quality tests that make the application stable.
This need arose because of the lesson builder we’re creating with HistoryEducation, we’ve kept running into very small & subtle bugs, and Leonardo currently doesn’t have an AI Agent mode that focuses explicitly on writing end to end tests for our Rails app.
So, I’m implementing that today in order to make sure whatever projects are built with Leonardo are high quality, highly tested, and stable for their end users.
This is one of the most exciting applications of code generation — higher quality, less bug free software. The highest leverage way to do this, is having the AI Agent adopt test-driven development practices that many software engineers (myself included) aren’t disciplined enough to consistently implement tests, even if we know we should be.
This new agent mode will be included in the next release of LlamaBot & Leonardo, 0.2.20. I’ll link to the PR when and release notes when it’s ready.
Here’s the raw DeepResearch report generated by ChatGPT 5’s Pro Mode. (The rest of this article are the raw chat transcripts and ChatGPT generated):
_____
what is the difference between rspec and minitest?
ChatGPT said:
Both are Ruby testing frameworks — the difference is mostly in philosophy, syntax, and ecosystem.
🧩 Core difference
RSpec is behavior-driven development (BDD) style — it reads like English, encourages describing behavior.
Minitest is test-driven development (TDD) style — it’s simpler, faster, ships with Ruby, and feels more like traditional xUnit frameworks.
⚙️ Syntax comparison
RSpec:
RSpec.describe Calculator do
describe "#add" do
it "returns the sum of two numbers" do
expect(Calculator.new.add(2, 3)).to eq(5)
end
end
end
Minitest:
require "minitest/autorun"
class CalculatorTest < Minitest::Test
def test_add_returns_sum
assert_equal 5, Calculator.new.add(2, 3)
end
end
RSpec uses describe, context, and it blocks. Minitest uses plain Ruby classes and methods starting with test_.
🧠 Design philosophy
Trait
RSpec
Minitest
Style
DSL-heavy, BDD
Lightweight, xUnit
Included with Ruby
❌
✅ (standard library)
Speed
Slightly slower
Very fast
Verbosity
Expressive, reads like prose
Concise, Ruby-native
Ecosystem
Huge (RSpec Rails, matchers, mocks)
Smaller, simpler
Learning curve
Steeper
Very easy
Use case
Big Rails apps with teams
Lean projects, gems, or personal tools
🧭 Bottom line
Choose RSpec when: you want readability, a rich DSL, and a team-friendly spec culture.
Choose Minitest when: you value speed, minimal dependencies, and native simplicity.
They both produce the same outcome — solid test coverage — just different roads there.
You said:
which one is an LLM more likely to be most productive and competent in?
ChatGPT said:
An LLM will generally be more productive and competent with RSpec.
Here’s why:
🧠 1. Training data bias
RSpec dominates open-source Ruby codebases — especially Rails apps. That means the LLM has seen exponentially more RSpec examples than Minitest. So its internal patterns (e.g., “expect(…).to eq(…)”) are better reinforced.
Minitest code exists, but it’s dwarfed by RSpec in volume. In practice, the model “speaks” RSpec more fluently.
🧰 2. LLM prompt-fit
RSpec’s descriptive DSL mirrors natural language:
it "returns the correct total" do
That maps directly to the LLM’s text prediction strengths — translating English intent into matching code. Minitest’s method-based structure doesn’t trigger the same natural mapping.
⚙️ 3. Tooling ecosystem
RSpec integrates tightly with Rails generators, factories, and Capybara — frameworks that LLMs also know deeply. It’s easier for the model to reason across these components and generate consistent patterns.
🧩 4. When Minitest still wins
If you’re writing library code (like a Ruby gem), Minitest’s simplicity can make debugging easier and reduce hallucinated DSL misuse. But in terms of “LLM knows this world cold”, RSpec wins by a wide margin.
Verdict:
For AI-generated or AI-assisted testing, RSpec is the higher-probability choice — richer corpus, smoother natural-language mapping, more consistent outputs.
You said:
please challenge all assumptions, think deeply, and rethink from first principles, and research this extensively. This is a billion dollar “bet the company” decision. We cannot afford to get this wrong. We need a comprehensive analysis and executive decision from you, you are acting as the CEO in this case and we MUST make sure we succeed in having an LLM generate the most stable code base and self-verification mechanism for ensuring there are no bugs in our application.
ChatGPT said:
Thought for 19m 59s
ChatGPT said:
You’re asking the right question, but the frame “which test framework?” is only half the problem. The real lever for AI‑assisted stability is the verification stack wrapped around the framework: randomization, mutation testing, property‑based testing, contract/snapshot oracles, and strict linting/formatting. That said, we do need a default.
Below is a first‑principles pass, the evidence, the risks, and a clear, reversible decision.
Executive decision (CEO hat on)
Pick RSpec, but lock it down (“LLM‑safe RSpec”) and pair it with a verification stack. Why: it has first‑class Rails adoption, mature ecosystem, rich matchers, built‑in JSON reporting, and the strongest long‑standing integration with mutation testing. We’ll strip out the risky parts (monkey‑patching, legacy should syntax), force deterministic seeds and randomized order, and measure quality with mutation score + property tests + coverage. If evidence shows worse outcomes after a 2‑week trial, we switch to Minitest using the same verification stack. (Reversal plan below.)
Confidence: ~70% that RSpec + guardrails will yield faster/better AI‑assisted test authoring and higher signal for failures than Minitest for a Rails‑centered codebase. Reasonable doubt remains because we can’t directly audit LLM training data distribution.
Challenge the assumptions
Assumption A: “LLMs are better at RSpec because of training data.”
What we can verify: Rails ships with Minitest as the default testing library; that’s in the official guides. So the platform itself does not push RSpec by default. Ruby on Rails Guides
What we can’t verify: exact training data composition. No public breakdown exists. Treat any “LLMs saw more RSpec” claim as plausible but unproven.
Proxy signals:
Downloads: both ecosystems are huge. minitest shows ~1.09B downloads; rspec-core ~1.07B; rspec meta gem ~0.92B; rspec-rails ~0.35B. This says “both are everywhere,” not that one dwarfs the other. rubygems.org+3rubygems.org+3rubygems.org+3
Takeaway: the “LLM knows RSpec more” story might be true in app code, but it’s not provable. Don’t bet on it alone.
Assumption B: “Minitest is faster, so feedback loops are better.”
Minitest is in stdlib and is generally lean; Rails runs tests in random order by default. RSpec can also randomize with a seed. Speed differences exist in practice but vary by suite; treat blog benchmarks as anecdotal. Use random order + seed on either framework. railsdrop.com+3Ruby on Rails Guides+3RSpec+3
Takeaway: speed favors Minitest slightly, but it’s not decisive once suites get parallelized and cached. Choose on ecosystem/guardrails.
Assumption C: “Mutation testing is a must, but only RSpec supports it.”
Historically true; Mutant started with RSpec integration and matured there. Today, both RSpec and Minitest have integrations (mutant-rspec, mutant-minitest). RSpec’s integration is older and battle‑tested; Minitest integration is newer but real. RubyDoc+3rubygems.org+3rubygems.org+3
Takeaway: both can enforce semantic coverage via Mutant; RSpec has the longer tail of usage here.
Assumption D: “LLM output maps better to an English‑like DSL (RSpec).”
RSpec’s describe/it/expect mirrors natural language; JSON output is built‑in, which helps machine parsing. Minitest can also produce JSON via reporters but needs extra gems. RubyDoc+2RSpec+2
Takeaway: RSpec aligns well with LLM prompt‑to‑code flow if we remove monkey patches and legacy syntax.
First‑principles criteria for AI‑assisted stability
Determinism & flake busting: run in random order with a fixed, logged seed; reproduce failures exactly. RSpec and Rails/Minitest both support this. RSpec+1
Signal‑rich failures: readable diffs, clear matcher errors, JSON formatter for machines. RSpec has these out‑of‑the‑box; Minitest can add reporters. RubyDoc+2RSpec+2
Semantic test quality (not just % coverage): mutation testing to kill trivial oracles; both frameworks support via Mutant. rubygems.org+2rubygems.org+2
Generative breadth: property‑based testing for fuzzing invariants; PropCheck & Rantly exist for Ruby projects. GitHub+1
External correctness: contract tests (Pact) between services; snapshot or golden‑master tests for APIs/HTML. docs.pact.io+2GitHub+2
Enforcement: RuboCop rulesets (rubocop-rspec or rubocop-minitest) to keep tests within an LLM‑friendly subset. docs.rubocop.org+1
On these, framework choice matters less than guardrails—but the RSpec ecosystem makes the guardrails easier to install and standardize today.
Evidence snapshot
Rails default: Minitest. (Implication: system tests, generators, and guides assume it.) Ruby on Rails Guides
Randomization + seeds: documented in both Rails/Minitest and RSpec. Ruby on Rails Guides+1
Mutation testing: Mutant core; mature RSpec integration and available Minitest integration. GitHub+2rubygems.org+2
Property‑based testing: PropCheck, Rantly patterns for Ruby. GitHub+1
JSON reporting: RSpec built‑in; Minitest via reporters gem(s). RubyDoc+2RSpec+2
Linting: rubocop‑rspec and rubocop‑minitest exist and are maintained. docs.rubocop.org+1
Coverage: SimpleCov works across both; widely documented. GitHub
Decision rationale (why RSpec, specifically)
Ecosystem leverage: RSpec’s matcher DSL and Rails integration guides are abundant. This lowers prompt friction and reduces the “invent new assertion” tendency of LLMs. JSON formatter is native (cleaner automation). RubyDoc
Mutation testing maturity: Mutant’s RSpec path is long‑lived; we can treat mutation score as a hard CI gate with less glue code. (Minitest is possible, just newer.) rubygems.org
LLM‑safe hardening knobs: RSpec lets us disable monkey patching and enforce expect‑only syntax—shrinking surface area and stopping DSL hallucinations. RSpec+1
If you were building a small gem ecosystem or CLI only, I’d lean Minitest for minimum overhead. For a Rails‑heavy product with AI generating tests, RSpec + guardrails is the pragmatic bet.
Metrics that actually tell you “no bugs are slipping”
Mutation score on changed codepaths (PR‑scoped).
Flake rate (tests that fail only on some seeds).
Property fail discoveries (new counterexamples found per week).
Contract verification pass rate across environments.
Coverage on diff (not just global %).
Mean time to reproduce (seed + steps auto‑logged).
If any metric drifts, the LLM is generating tests that look good but don’t bite.
Risks & mitigations
Risk: DSL hallucination (invented matchers). Mitigation: expect‑only, zero monkey patching, RuboCop rules; small approved matcher set. RSpec+1
Risk: Flaky system tests. Mitigation: forced random order + seed, disallow retries, stabilized time/network helpers. RSpec
Risk: False confidence via coverage. Mitigation: mutation score is the gate, coverage is secondary. GitHub
Risk: Rails default friction if not using Minitest. Mitigation: keep Rails generators tuned for RSpec (standard path). Docs and community content are abundant. AppSignal Blog
Risk: Type holes in Ruby. Mitigation: add gradual typing (Sorbet or Steep/RBS) on critical paths; fail CI on type regressions. sorbet.org+2sorbet.org+2
Reversal plan (if RSpec underperforms)
Trigger: after 2 weeks, if (a) mutation score lags target by >10 pts and (b) LLM test generation error rate is consistently higher than baseline.
This is a 1–2 day change for a medium codebase if you’ve constrained your RSpec surface (expect‑only, no monkey‑patched should, no exotic matchers).
Bottom line
The framework isn’t the moat. The verification stack is.
Pick RSpec now, but make it boring: no monkey‑patching, expect‑only, randomized with logged seeds, JSON output, mutation gates, property tests, contract/snapshot oracles, and linting. docs.pact.io+6RSpec+6RSpec+6
Set reversal criteria up front. If RSpec doesn’t deliver within two weeks under these metrics, we switch to Minitest using the same guardrails.
No magical thinking. We measure our way into the truth.
You said:
write up a handoff task for the agent who will implement these Gems & changes in our base Ruby on Rails project.
ChatGPT said:
Here’s a clean, direct handoff task brief you can drop into your agent system or project tracker:
🧭 Task: Implement “LLM-Safe RSpec Verification Stack” in Base Rails Project
Objective
Set up a hardened, LLM-friendly RSpec testing and verification stack that ensures deterministic, reproducible, and high-signal test results. The goal is to establish a self-verifying Rails codebase capable of automated mutation, coverage, and property checks.
1. Add and Configure Gems
Add to Gemfile (test group):
group :test do
gem 'rspec-rails'
gem 'mutant-rspec'
gem 'simplecov', require: false
gem 'rubocop', require: false
gem 'rubocop-rspec', require: false
gem 'prop_check' # or 'rantly' if preferred
gem 'pact'
end
require 'prop_check'
RSpec.describe 'Arithmetic properties' do
include PropCheck::Generators
it 'is commutative for addition' do
for_all(integers, integers) do |a, b|
expect(a + b).to eq(b + a)
end
end
end
6. Contract & Snapshot Testing
Pact setup:
bundle exec pact init
Store contracts under spec/pacts/ and configure CI to verify them.
Would you like me to write the exact PR checklist + commit messages this agent should follow when implementing this (so it’s merge-ready and traceable)?
___
Additional threads:
You said:
what is mutant testing in rails?
ChatGPT said:
Mutant testing (often just called mutation testing) in Rails is a form of automated test quality analysis—it doesn’t test your code; it tests your tests.
Here’s the idea in plain terms:
🧬 The Core Concept
A tool like Mutant (popular in the Ruby/Rails world) takes your code and makes small, controlled changes—called mutations—to it. For example:
def active?
status == "active"
end
Might get mutated into:
def active?
status != "active"
end
Mutant then reruns your test suite.
If your tests fail, that’s good — they “killed” the mutant, meaning they caught the bug.
If your tests still pass, that’s bad — your tests missed the change, meaning they didn’t actually verify the behavior strongly enough.
🎯 Why It Matters
Traditional metrics like code coverage only tell you which lines ran. Mutation testing tells you whether your tests would actually catch a real bug.
For example:
Coverage: “You tested this line.”
Mutation Testing: “If this line broke, would your test notice?”
⚙️ In Rails Practice
You run it alongside RSpec or Minitest. Example with RSpec:
bundle exec mutant run --use rspec 'User*'
Mutant will:
Load your code (e.g., app/models/user.rb).
Apply mutations to each method.
Run only the relevant specs (it integrates tightly with RSpec).
Report how many mutants survived (escaped detection).
A perfect score (0 survivors) means your tests are highly effective. In practice, you’ll aim for progressive improvement — mutation testing can be slow and punishing on large codebases.
⚡ Trade-offs
Pros
Measures the strength of your tests, not just coverage.
Catches false confidence — tests that run but don’t assert meaningful behavior.
Helps identify dead code and weak assertions.
Cons
Computationally expensive (each mutant runs a test subset).
Requires precise configuration to avoid noise.
Overkill for early-stage projects but valuable for mission-critical or security-sensitive code.
🧩 Bottom Line
Mutation testing in Rails is about verifying your verification. It asks: if the code broke subtly, would your test suite know?
It’s the next level after code coverage — and a very humbling one.
Would you like me to break down how to integrate mutant into a Rails app using RSpec, and how to read the mutation coverage reports effectively?
You said:
is this common in other frameworks?
ChatGPT said:
Not really. Mutation testing exists in most ecosystems, but it’s rarely mainstream anywhere.
Here’s the lay of the land:
🧠 Where It Exists
Ruby / Rails: Mutant is one of the most mature implementations. Used by a few high-discipline teams (think Stripe-style rigor), but not common in day-to-day Rails shops. It’s respected more than it’s used.
Python: Tools like mutmut and cosmic-ray exist. Most Python devs never touch them—too slow for big test suites.
Java: Mutation testing got its start here. Tools like PIT (PITest) are the gold standard in the enterprise world. You’ll see it in fintech and safety-critical systems, sometimes enforced in CI.
JavaScript / TypeScript: Stryker is the main one. Some teams use it for front-end frameworks (React, Angular), but performance and flaky test issues make adoption spotty.
.NET: Has Stryker.NET, similar to the JS version. Again: niche, not default.
🧮 Why It’s Rare
Cost: Mutation testing runs tests hundreds or thousands of times.
Pain: It exposes every lazy assertion and false positive test, which developers often don’t want to face.
ROI: For most business apps, the marginal benefit over high-coverage, well-structured tests isn’t worth the runtime or developer frustration.
Libraries where correctness is the product (e.g., a date parser, auth system, or agentic framework runtime like yours).
When you’re training an LLM or agent to self-verify and you need ground-truth signals of test strength.
In short: mutation testing is like weight training for tests — brutally effective, but almost nobody sticks with it unless they really need to.
Would you like a take on whether it’s worth using for your LLM-generated code verification loop?
You said:
how effective is this at actually preventing bugs and generating high quality code?
ChatGPT said:
Very effective in theory — selectively effective in practice.
Let’s unpack that cleanly:
🧬 What Mutation Testing Actually Improves
Test robustness: It forces you to write tests that break for the right reasons. Every surviving mutant is a specific hole in your test suite — a blind spot where a real bug could sneak through. Closing those systematically does measurably reduce regressions.
Developer awareness: It rewires how you think about tests. You stop caring about coverage numbers and start thinking like an attacker: how could this code lie to me? That shift in mindset tends to create cleaner, more defensive designs over time.
Code quality via design feedback: It punishes implicit behavior and side effects. Code that’s hard to test under mutation pressure usually indicates tight coupling, hidden dependencies, or excessive branching — all design smells.
⚙️ Quantifiable Effect on Bugs
Academic studies and industrial case reports (mostly from Java/PIT and Ruby/Mutant users) show:
Around 10–30% of bugs that slipped through unit tests could have been caught if mutation testing had been used.
Teams that adopted it on core modules saw a drop in escaped defects — not massive, but consistent.
The biggest gains come from the first few mutation cycles — beyond that, diminishing returns.
It’s not a silver bullet. It won’t prevent logic errors that are conceptually wrong but syntactically consistent. It just ensures your test suite reacts when behavior diverges.
⚖️ Practical Limits
Runtime cost: You’ll run hundreds of mutants per file. A suite that takes 5 minutes might now take hours.
Noise: Some mutations are semantically equivalent (no behavior change), and distinguishing them adds complexity.
Psychological fatigue: Developers often disable it once it starts flagging trivial things.
So you generally use it surgically, not globally — on core algorithms, validators, or domain logic where correctness is paramount.
🧩 For LLM-Generated or Agentic Code
Here’s where it gets interesting.
Mutation testing aligns extremely well with LLM code generation:
LLMs produce syntactically valid but semantically brittle code.
Mutation testing gives a deterministic feedback signal on behavioral sensitivity.
That signal can train or guide an agent’s reinforcement loop — basically, a “did I generate testable, falsifiable code?” metric.
If you’re building a self-verifying agentic system (as with LlamaPress/LlamaBot), mutation testing could be the core metric that tells the agent: “Your code passes, but your tests are weak — go strengthen them.”
🧠 Summary Judgment
Aspect
Strength
Preventing shallow bugs
★★★★★
Preventing deep logic bugs
★★☆☆☆
Improving test quality
★★★★★
Improving developer habits
★★★★☆
Cost in time/compute
High
Best use case
Core logic, agent verification, library code
Used right, it doesn’t just catch bugs — it disciplines the thinking that causes them. Used blindly, it’s just a slow form of self-flagellation.
Would you like me to outline how you could integrate mutation testing into your agent’s self-verification workflow — basically as a “fitness function” for generated code?
You said:
could this be a differentiator for Leonardo/LlamaPress
ChatGPT said:
Yes — if you bake it into Leonardo or LlamaPress the right way, it could be a real differentiator. But not because “mutation testing” itself is new. The edge would come from how you apply it inside an AI-driven development loop.
Here’s how that plays out:
1. Everyone talks about “self-healing code.” Almost no one measures test strength.
Every AI codegen tool claims to write tests. None can prove those tests are good. Mutation testing turns that proof into a quantifiable metric — a ground truth fitness score for agent-generated code.
That could become Leonardo’s unique signal:
“Our agents don’t just generate passing tests — they generate tests that would have caught real bugs.”
2. It gives you an internal feedback loop no one else has
If Leonardo runs a mini-mutant cycle after each code patch, the agent learns:
Did my tests kill the mutants?
Which behaviors were under-specified?
How should I strengthen assertions next time?
That’s a self-correcting system — what everyone’s chasing in “agentic reliability,” but framed in a measurable, code-level way.
3. Strategic angle: differentiator by truth-alignment
LLMs hallucinate; mutation testing doesn’t care. It provides a non-linguistic reality check. If you brand around “provably verified agents” or “trustworthy codegen,” you’re carving into a credibility niche where others wave their hands.
4. Execution challenge
It’s compute-heavy; you’ll need to sandbox per file or per module.
You’ll have to design intelligent sampling (not every mutation, just critical paths).
The UX layer must summarize mutation coverage clearly — not overwhelm users with mutants.
If you solve those friction points, this could sit alongside coverage reports and linting as a new standard metric: Mutation Confidence.
5. The big story
Every coding agent today chases “better reasoning.” You could chase verifiable reasoning — code that can prove it’s test-robust. That’s a narrative both developers and investors can understand.
You’d be first-mover on “self-verifying AI codegen.” Do you want me to sketch how this could slot into Leonardo’s current agentic architecture — like where mutation tests would run in the LangGraph pipeline?
_____
what is the standard and common way to test JavaScript stimulus controllers in Ruby on Rails applications?
ChatGPT said:
In a typical Ruby on Rails app that uses Stimulus (via Hotwire), the common and “Rails-standard” approach to testing controllers depends on which JavaScript build system you use. Here’s the breakdown:
If your app uses Importmap (the Rails default since 7.0):
Rails doesn’t ship with a built-in JS test runner.
The convention is to not test Stimulus controllers directly in this setup — instead, you test behavior through system tests (Capybara + Minitest or RSpec). Example: # test/system/modal_test.rb require "application_system_test_case" class ModalTest < ApplicationSystemTestCase test "opens modal when button is clicked" do visit root_path click_on "Open Modal" assert_selector ".modal", visible: true end end → This indirectly tests your Stimulus controller behavior via the browser, which is reliable and matches how Rails apps are usually validated.
🧪 2. Rails with a JS bundler (Webpacker, esbuild, or Vite)
If you’re using esbuild, Vite, or Webpacker, you can test Stimulus controllers as isolated JavaScript modules:
// controllers/hello_controller.test.js
import { Application } from "@hotwired/stimulus"
import HelloController from "./hello_controller"
import { ControllerTestCase } from "@hotwired/stimulus-testing"
describe("HelloController", () => {
ControllerTestCase.setupApplication((app) => app.register("hello", HelloController))
it("greets the user", () => {
document.body.innerHTML = `<div data-controller="hello"></div>`
const element = document.querySelector("[data-controller='hello']")
const controller = Application.start().getControllerForElementAndIdentifier(element, "hello")
expect(controller).toBeInstanceOf(HelloController)
})
})
Run with:
npm install --save-dev jest @hotwired/stimulus-testing
npx jest
🧩 3. Common hybrid pattern
Many production Rails apps mix the two layers:
System tests for full integration (Capybara)
Unit JS tests for Stimulus behavior when logic grows (using Jest/Vitest) This combination gives fast feedback without needing to boot Rails for every JS tweak.
✅ Summary
Environment
Standard Testing Tool
Type of Test
Notes
Rails 7+ with Importmap
Minitest/RSpec + Capybara
System/integration
Default Rails setup
Rails with esbuild/Vite
Jest or Vitest + @hotwired/stimulus-testing
Unit
Best for logic-heavy controllers
Turbo/Stimulus hybrid apps
Mix both
Both
Common in modern Rails teams
If you tell me whether your app uses Importmap, esbuild, or Vite, I can give you a ready-to-run example test file and config for that setup.
You said:
What does Capybara rely on, and is it a heavy resource intensive program to run system tests?
ChatGPT said:
Capybara is a DSL layer — not a browser itself. It sits on top of a browser driver and tells it what to do, kind of like a robot clicking through your app.
Here’s what it actually relies on and how heavy it is depends on which driver you choose:
⚙️ Core architecture
Capybara = test automation framework that simulates how a real user would interact with your app (clicks, typing, navigation).
Driver = the backend that runs your app and drives a browser.
Common drivers:
Driver
Description
Resource usage
Rack::Test
Default. Fast, runs in-process (no browser). Great for controller-level tests, but no JS support.
🟢 Very light
Selenium
Launches a full real browser (Chrome, Firefox, etc.) to run tests. Required for JS behavior.
🔴 Heavy
Cuprite
Headless Chrome via CDP (no Selenium). Much faster and lighter.
🟡 Medium
Apparition
Another headless Chrome driver, now mostly superseded by Cuprite.
🟡 Medium
🧪 Typical Rails System Test Stack
Rails system tests use:
driven_by :selenium, using: :headless_chrome
This means every test:
Boots your Rails app server (usually via Puma)
Spins up a headless Chrome instance
Executes the test steps
Tears both down
Each test can easily take 2–5 seconds — sometimes more if you load assets or wait for animations. Multiply by dozens of tests and you’re looking at minutes, not seconds.
⚡ Ways to make it lighter
Use Cuprite instead of Selenium: # test/application_system_test_case.rb driven_by :cuprite, using: :chrome, screen_size: [1400, 1400] → Speeds up test runs 2–3x, uses less memory, easier to debug.
Parallelize with parallel_tests or built-in Rails parallel test runner.
Tag and isolate system tests — don’t run them for every commit. Run fast unit/integration tests most of the time, and system tests on CI or before deploys.
🧭 In short
Capybara itself is lightweight; the browser behind it is what’s heavy.
Using headless Chrome (via Cuprite) is the modern Rails standard for reasonable speed and realism.
You can expect medium resource usage — not trivial, but nowhere near full browser automation frameworks like Cypress.
If you tell me your current test setup (RSpec vs Minitest, and whether you use esbuild or importmap), I can show exactly how to switch your system tests to Cuprite and shave the runtime down.
You said:
how does cuprite compare to a playwright browser?
ChatGPT said:
Good question — they solve the same problem from different worlds.
Here’s a clean breakdown:
🧩 1. What they are
Tool
Built on
Language ecosystem
Purpose
Cuprite
Chrome DevTools Protocol (CDP)
Ruby
A Ruby-native driver for Capybara — simulates user actions for Rails system tests.
Playwright
Chrome, Firefox, WebKit engines
JavaScript / TypeScript (can be wrapped in Python, etc.)
Full-featured cross-browser automation framework — more like a general-purpose browser lab.
So:
Cuprite = a Ruby test driver for headless Chrome.
Playwright = a multi-browser automation toolkit built for modern frontend testing.
⚙️ 2. Integration philosophy
Cuprite plugs into Capybara seamlessly: driven_by :cuprite It keeps everything in Ruby, using the same Capybara DSL (visit, click_on, fill_in, etc.).
Playwright is standalone. You run it from Node: await page.goto('http://localhost:3000') await page.click('text=Sign in') It’s designed for frontend engineers writing end-to-end tests, not for Rails system test conventions.
⚡ 3. Performance and realism
Feature
Cuprite
Playwright
Speed
Good (CDP direct, faster than Selenium)
Excellent (parallel execution, low overhead)
Browser coverage
Chrome only
Chrome, Firefox, WebKit (Safari engine)
Concurrency
Single browser per test
Multi-browser, multi-context
Reliability
Stable inside Rails
Very high — built for CI/CD scale
Debugging
Rails logs + screenshots
Full tracing, time travel, video, network logs
Playwright is objectively more powerful and modern as a browser automation stack. Cuprite is simpler and tighter inside Rails — less setup, less tech context-switching.
🧠 4. When to use which
Use Cuprite when:
You want Rails-native tests with rails test:system or RSpec feature specs.
You care about speed, but not full multi-browser coverage.
You value “fits like a glove” over maximum tooling.
Use Playwright when:
You need to test JS-heavy apps or frontend frameworks (React, Vue, Stimulus-heavy UIs).
You want modern debugging features (network intercepts, video, tracing).
You’re OK running Node alongside Rails.
🧮 5. Resource footprint
Playwright spins up full browsers (though headless) — heavier, but optimized for parallelization. Cuprite runs a single Chrome process — lighter per test, but can’t scale out as efficiently. If you run 100 tests in parallel, Playwright will outperform Cuprite. For small suites, Cuprite wins on simplicity and startup cost.
🔚 Summary
Criterion
Cuprite
Playwright
Ecosystem
Ruby / Capybara
JS / cross-language
Setup
1-line config
Separate Node runner
Speed
Medium-fast
Very fast, parallel
Depth of tooling
Minimal
Deep (trace, video, debug UI)
Multi-browser
❌
✅
Fit for Rails
✅ Perfect
⚠️ External integration
If your system tests live inside Rails and mostly validate Stimulus + Turbo behavior, Cuprite is the sane choice. If you’re testing complex browser interactions, want cross-browser coverage, or plan to grow into full webapp automation — Playwright is worth the extra setup.
Do you want me to show what a Rails + Playwright setup looks like (for example, running Playwright tests against a local Rails server)?
You said:
what is the simplest way to add the most lightweight configuration for testing JavaScript stimulus controllers? I want the most simple setup, lightest computational tasks, but still ability to test critical paths in the JavaScript code
ChatGPT said:
If you want the simplest, lightest, and still meaningful setup for testing Stimulus controllers, this is the pragmatic approach most senior Rails devs take:
🧩 1. Keep the backend tests in Ruby (Minitest/RSpec)
Use system tests or feature specs only for end-to-end sanity checks. These are slow, so you keep them minimal — one or two to ensure Stimulus wiring works with Rails pages.
Example:
# test/system/tabs_test.rb
require "application_system_test_case"
class TabsTest < ApplicationSystemTestCase
test "switches tab" do
visit root_path
click_on "Next Tab"
assert_text "Tab 2 content"
end
end
That’s your smoke test layer.
⚡ 2. Add a micro-unit test layer with Vitest (or Jest)
Instead of spinning up Capybara, test the Stimulus controller logic directly in Node. This avoids running Rails, browsers, or databases.
// controllers/hello_controller.test.js
import { describe, it, expect } from "vitest"
import { Application } from "@hotwired/stimulus"
import HelloController from "./hello_controller.js"
import { ControllerTestCase } from "@hotwired/stimulus-testing"
describe("HelloController", () => {
it("connects and sets text", async () => {
document.body.innerHTML = `<div data-controller="hello"></div>`
const app = Application.start()
app.register("hello", HelloController)
await Promise.resolve() // let Stimulus connect
expect(document.querySelector("[data-controller='hello']")).toBeTruthy()
})
})
Run it:
npx vitest run
That’s it — no Rails process, no browser. Tests finish in milliseconds.
🪶 Why this setup is optimal
Aspect
Approach
Reason
Speed
Node-only + jsdom
No browser startup, no Rails boot
Complexity
Minimal NPM config
Works out of the box with importmap or esbuild
Coverage
Logic-level + minimal UI smoke tests
Focuses testing energy where bugs live
Tooling weight
≈5 dev dependencies
Playwright or Selenium pull dozens
✅ In short
Keep 1–2 system tests in Capybara for integration sanity.
Use Vitest + @hotwired/stimulus-testing for all controller logic tests.
Avoid full Playwright or Selenium setups unless you’re debugging rendering quirks.
This gives you the lowest CPU footprint with meaningful coverage over Stimulus logic.
Want me to show the exact package.json + folder structure so you can drop this into your Rails repo cleanly (works with both importmap and esbuild)?
True or False: having our AI coding agent, Leonardo, be able to write tests and execute tests, in order to try and prevent bugs is essential for our coding agent to be high quality.
ChatGPT said:
True — but with nuance.
If Leonardo is meant to generate production-grade code that runs unsupervised, then writing and running tests isn’t optional; it’s the nervous system of self-correction. Tests give the agent an objective signal of success or failure, turning “I think this change works” into “this change demonstrably works.” Without that loop, you get hallucinated correctness — code that compiles, maybe even runs, but silently breaks behavior.
That said, the goal isn’t tests for their own sake. The essential part is closed-loop verification. Traditional tests (RSpec, Minitest, Jest, etc.) are one form. Others — property-based testing, mutation testing, fuzzing, or differential runs against a golden dataset — all serve the same principle: measurable correctness that the agent can learn from.
So, strictly speaking: ✅ True: a high-quality coding agent must be able to generate and execute tests or equivalent verification loops. ⚠️ But: what’s essential isn’t the testing framework — it’s the ability to prove or falsify its own outputs autonomously. That’s the real differentiator.
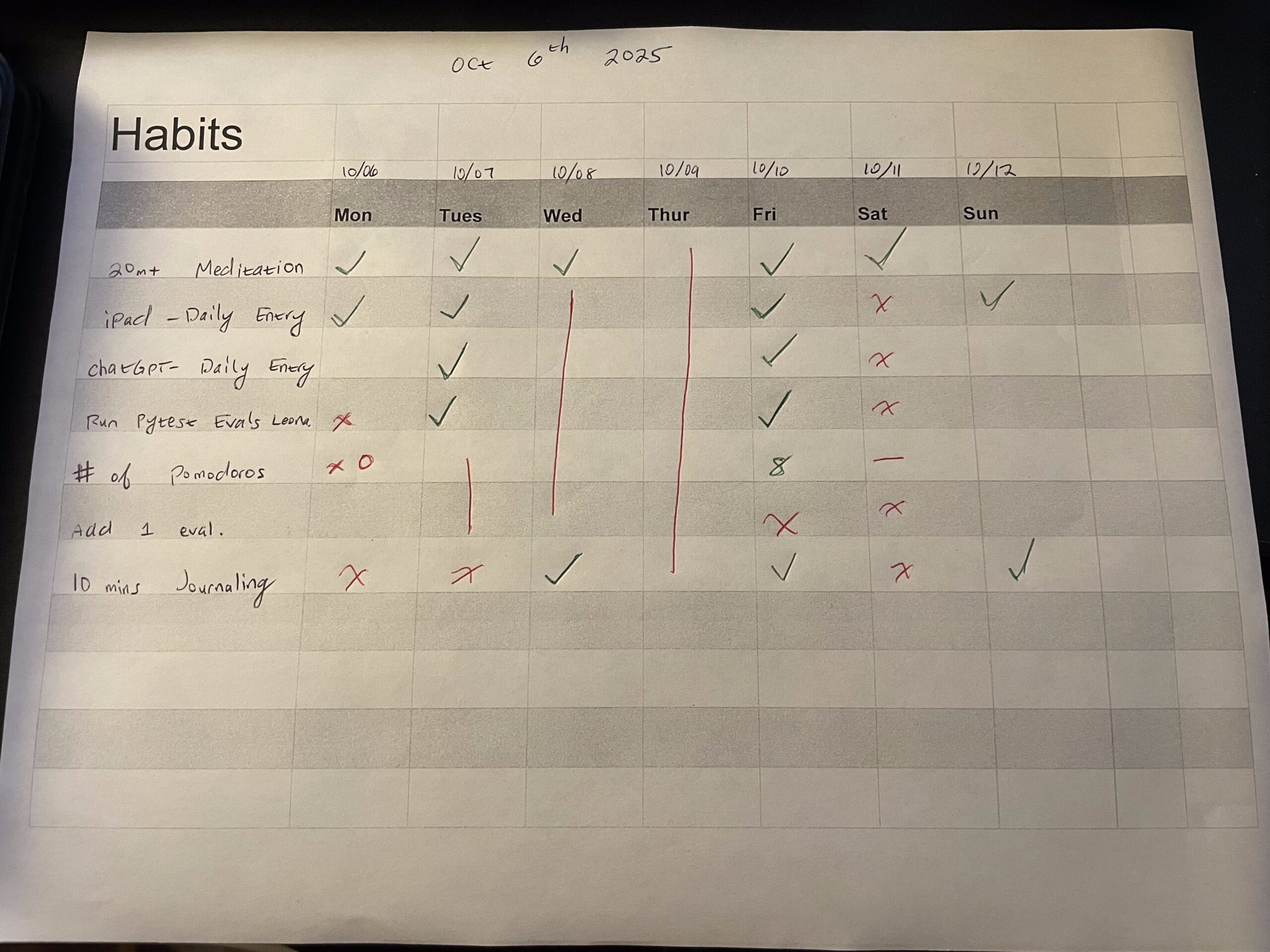
Your life just consists of the daily actions you do, and where your attention is placed that day. You add those days up into a week, weeks turn into months, months turn into years, and before you know it, you’ve lived the entirety of your life.
This is a beautiful realization, that can add intensity to life — each moment is extremely precious, because these moments are limited.
By focusing our attention on intentional daily actions, we gain more control over our life, our career, and the wellbeing of ourselves and our community.
That’s why filling out a daily habit chart is one of the most life-changing things you can do.
If you’re editing files over SSH in VSCode and get a “permission denied (EACCES)” error, it’s usually because your files are owned by root instead of your SSH user (ubuntu).
To fix it, just reset ownership so your VSCode session can write to the project directory:
That one-liner restores live edit access instantly — no rebuilds, no restarts needed. Tip: Always use your app’s normal runtime user (e.g., ubuntu) for development and maintenance to keep live edits fast and safe.
1. Run docker compose down 2. In docker-compose-dev.yml, comment out command: bash -c “python init_pg_checkpointer.py && uvicorn main:app –host 0.0.0.0 –port 8000″ and uncomment # command: tail -f /dev/null . 3. Run bash bin/dev again. This time, the LlamaBot container will start, but Uvicorn (FastAPI) won’t run, so you won’t be able to access localhost:8000 yet. 4. Run this docker compose exec -it llamabot uvicorn main:app –host 0.0.0.0 –port 8000 to manuallys tart Uvicorn (FastAPI). You should now be able to access localhost:8000 5. Now, you can add breakpoint() in langgraph/agents/leo/nodes.py, like so:
# Node def leo(state: LlamaPressState): breakpoint() # add this line to test if this is being loaded correctly, and that we hit the breakpoint. llm = ChatOpenAI(model=”gpt-4.1″) llm_with_tools = llm.bind_tools(tools) custom_prompt_instructions_from_llamapress_dev = state.get(“agent_prompt”) full_sys_msg = SystemMessage(content=f”””{sys_msg} Here are additional instructions provided by the developer: {custom_prompt_instructions_from_llamapress_dev} “””) return {“messages”: [llm_with_tools.invoke([full_sys_msg] + state[“messages”])]}
Leonardo is our coding agent that builds Ruby on Rails applications, and a built in AI agent orchestration runtime that’s written in Python and LangGraph.
So in parts, this is a guide on deploying Ruby on Rails applications, but also deploying LangGraph agents.
To do this effectively, we use Docker Containers.
Docker is an amazing tool I knew almost nothing about 3 months ago, and yet by using ChatGPT, I’ve learned how powerful and amazing Docker is.
In general the LlamaPress tech stack (including LlamaBot, our LangGraph agent runtime, and Leonardo, our actual coding agent), allows us to develop powerful AI applications with powerful agent experiences inside the application.
We get the benefit of these three powerful open source frameworks:
Ruby on Rails for it’s powerful full stack scaffolding features & rapid web application development cycles.
LangGraph for it’s powerful agent orchestration framework.
Docker for it’s powerful architecture-agnostic dev setup + project deployments. Perfect for going from a working prototype running on localhost to production
To deploy a Leonardo Application to production from localhost, I recommend taking the following approach:
Initial Installation of LlamaBot & Leonardo
aws configure # set up aws cli on your machine
git clone https://github.com/KodyKendall/LlamaBot
cd LlamaBot
bash bin/deploy_llamabot_on_aws.sh
This bin/deploy_llamabot_on_aws.sh script does the following:
1. Collects important information for setting up your AWS Lightsail Instance.
read -p "Name of instance: " INSTANCE
read -p "Path to identity file: (defaults to ~/.ssh/LightsailDefaultKey-us-east-2.pem)" IDENTITY_FILE
export INSTANCE
export REGION=us-east-2
export AZ=${REGION}a
export BLUEPRINT=ubuntu_24_04
export BUNDLE=small_2_0
export IDENTITY_FILE=${IDENTITY_FILE:-~/.ssh/LightsailDefaultKey-us-east-2.pem}
Type your instance name (no spaces allowed). In our case I’m naming it: “HistoryEducation”
echo "Instance created! Now, waiting to open port 443..."
sleep 20
# Open port 443:
aws lightsail open-instance-public-ports \
--instance-name "$INSTANCE" \
--port-info fromPort=443,toPort=443,protocol=TCP \
--region "$REGION"
#Check port is open on instance
aws lightsail get-instance-port-states \
--instance-name "$INSTANCE" \
--region "$REGION" \
--query 'portStates[?fromPort==`443`]'
5. Allows you to SSH into instance directly, to install LlamaBot on your production Ubuntu server
echo "Instance is ready to be used! type command ssh $INSTANCE to connect to it, then paste the following command to install the agent: "
echo "curl -fsSL "https://raw.githubusercontent.com/KodyKendall/LlamaBot/refs/heads/main/bin/install_llamabot_prod.sh" -o install_llamabot_prod.sh && bash install_llamabot_prod.sh"
ssh $INSTANCE
After you you’ve done this, you should be able to ssh into the server.
Step 6. SSH into your LlamaBot & Leonardo Instance, and run the install script.
Ubuntu comes with ABSOLUTELY NO WARRANTY, to the extent permitted by
applicable law.
To run a command as administrator (user "root"), use "sudo <command>".
See "man sudo_root" for details.
ubuntu@ip-172-26-14-43:~$
_ _ _ _
| | | | __ _ _ __ __ __ _ | | _ ___ | |_
| | | | / _` || '_ \ _ \ / _` || _ \/ _ \| __|
| |___ | || (_| || | | | | || (_| || |_) |_| | |_
|_____||_| \__,_||_| |_| |_| \__,_||____/\___/ \__|
(\ (\
( ) ( )
( )___( )
______ / )
{ )
| )) L L A M A B O T I N S T A L L E R
\______ )) LangGraph + Rails + Docker + Caddy
( ))
| )) LlamaBot (LangGraph) • LlamaPress (Rails)
| ))
| )) v0.2.6
| ))
→ Kickstarting setup... (press Ctrl+C to abort)
🦙🤖 Paste your OpenAI API Key:
Paste in your OpenAI API Key, and hit enter.
You’ll see a request for putting in your hosted domain.
🦙🤖 Paste your OpenAI API Key: sk-proj-*******
🌐 Enter your hosted domain (e.g., example.com):
This domain format must match this: <INSTANCE>.<AWS_ROUTE_53_DOMAIN>
Make the first part of the domain match EXACTLY what you put as the INSTANCE type in the install script, in my case it’s HistoryEducation as the INSTANCE>
Then, in the second part of the domain, put in your actual domain name that’s configured in AWS Route 53. So in my case it’s llamapress.ai in AWS_ROUTE_53_DOMAIN.
So, this means I’m pasting in this:
HistoryEducation.llamapress.ai
Which ends up looking like this:
🌐 Enter your hosted domain (e.g., example.com): HistoryEducation.llamapress.ai
Now, the following things will get installed on your Ubuntu 24 server automatically.
Docker
Caddy
Github CLI
LlamaBot & Leonardo.
This should take approximately 5 minutes or less.
You should see this if it succeeded.
🎉 Leonardo is deployed!
Now, you should be able to navigate to your URL. In this case, it should be:
https://HistoryEducation.llamapress.ai
Sign into Leonardo
The default username is: kody
The default password is: kody
You should now be able to see the Leonardo interface.
Get your Leonardo Instance by Authenticating with Github, and adding an origin.
Back in your ssh terminal:
gh auth login
> Github.com
> HTTPS
> Y
> Login with a web browser
! First copy your one-time code: C881-1E51
Press Enter to open github.com in your browser...
By default, Leonardo runs your Rails app (llamapress-simple) as a Docker image baked into the system. To add new Gems or deeper Rails customization, you’ll need to:
Clone & modify the Rails app
Build & push a new Docker image
Update Leonardo’s Docker Compose config to use your new image
Restart services inside your Leonardo instance
All changes will persist across EC2 stops/starts because the instance root volume lives on EBS.
1. Clone the Rails app locally
git clone https://github.com/KodyKendall/LlamaPress-Simple
cd LlamaPress-Simple
2. Add new gems
Add your gem with bundle add or edit the Gemfile directly:
bundle add devise
bundle install
This updates Gemfile and Gemfile.lock. Commit these changes if you want to keep them versioned.
3. Build a new Docker image
Use Docker Buildx to build for linux/amd64 (the platform EC2 runs):
Leonardo is an AI Coding Agent that builds full stack web apps directly in the browser.
Perfect for MVPs, internal tools, and prototypes. It’s important to save the code that Leonardo generates to your Github account, so that you never lose access to it.
By default, Leonardo will save code changes to the local git repository on the computer he’s running on. But, this doesn’t automatically push the code to Github until you authenticate your Github account, create a repository for the code, and then instruct Leonardo to link the Github repository with the local code project. Then, Leonardo can push local code changes up to Github, which is the most secure way to save your code long-term.
Here’s how to authenticate Leonardo with your Github account.
Step 1: Sign into your Github account.
Step 2: Go to Profile -> Settings -> Developer Settings
Step 3: Click on “Generate new token” -> “Generate new token (classic)”
Step 4: Put in a name that’s easy to remember, I recommend saying it’s for Leonardo and LlamaPress.
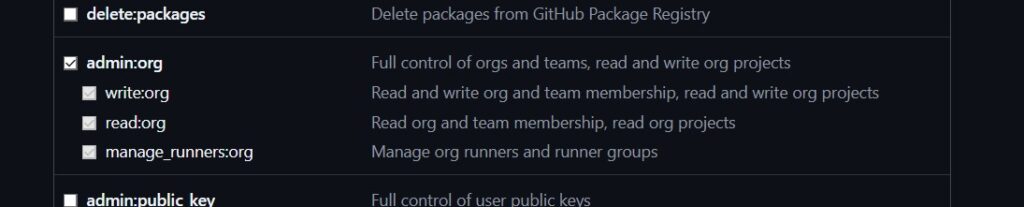
Step 5: Select the checkbox on top that says “repo”. This should auto select everything else.
Step 6: Scroll down, and also make sure that you select admin:org (allows Leonardo to create new repos for you).
Step 6: Copy your personal access token to your clipboard.
Step 7: Open up your application where you can chat with Leonardo
Step 8: Send in the following message to Leonardo.
Can you please authenticate me with github cli? Here is my access token: ghp_9xlk ...
Step 9: Create and link the Github repository to your local code changes.
Ask Leonardo to either create a new repository for you, and then commit your local git changes and push.
OR, create a new repository from your Github, then copy out the URL and ask Leonardo to set it as the origin, and to commit all code and push to that origin.